
Путь от Windows к Linux: организация поиска в русских RTF файлах

Одной из серьезных проблем при переходе на Linux для меня стала организация поиска по текстовым файлам. А именно по файлам в формате RTF. Как ее организовать в Linux?
При появлении на нашем IT рынке разных операционных систем, а соответственно, разных текстовых процессоров (я не имею в виду текстовые редакторы для программистов, а исключительно программы для гуманитариев) возникла проблема интеграции форматов.
Мне ответят, что MS Office, Openoffice и другие монстры читают все форматы. А также мне скажут: сохраняй в TXT и будет тебе счастье. Но... Во-первых, не люблю я тяжеленных монстров - зачем стрелять из пушки по воробьям, если тебе надо всего-лишь набрать несколько тысяч знаков текста без особого форматирования. Во-вторых, попробуй объясни секретарше, как в Windows (далее - ОС) открыть TXT, созданный в Linux. Поэтому я раз и навсегда определил себе круг текстовых редакторов (о чем в следующей статье), которые умеют сохраняться в RTF. Вот воистину универсальный формат без напильника. Но есть в нем одна сложность.
Практически все desktop (можно не проверять - все испробовано) поисковики спотыкаются на поиске текста в русских RTF файлах. В ОС был Архивариус и dtSearch, которые надо было воровать. В Linux я поначалу не нашел альтернативы. Пересохранять около 5 тысяч RTF файлов в другой формат как-то не очень. Потом я нашел два поисковика, в которых функция поиска внутри RTF была заявлена. Docfetcher и Recoll (есть и другие, но я искал поисковики без демонов). И они работают с RTF. Но, как оказалось, не c русскими RTF.
Я не специалист. Но, судя по форматам, в которые предлагает сохранять Abiword, есть два вида RTF — просто Rich Text Format и Old Rich Text Format. Docfetcher работает с русскими Rich Text Format, но не работает с русскими Old Rich Text Format. При том, что сохраняемый даже процессорами-монстрами RTF является Old Rich Text Format. Recoll не работал ни с теми, ни с другими.
Пришлось начать переписку с разработчиками. Автор Docfetcher даже перевыпустил релиз, но так и не смог решить проблему. Подробно переписку с ним можно посмотреть на соответствующем ресурсе sourceforge.net.
Разработчик Recoll — Jean-Francois Dockes — отнесся к моей проблеме серьезно, за что ему огромное спасибо. Он называл возможные причины бага и предлагал варианты его исправления. Я был тестировщиком. И в конце концов мы сделали это. Вся проблема оказалась в принятом по умолчанию в Linux конвертере RTF-файлов - пакете unrtf. А именно в том, что в репозиториях даже последних версий Linux дистрибутивов лежит пакет версии 0.19. А он, по словам Jean-Francois, «is quite old and couldn't do much with non ascii files», то есть не может нормально работать с не ascii файлами. Последняя стабильная версия unrtf 0.21.1, как он сказал, не многим лучше. Поэтому мне было предложено скачать с сайта Unrtf последнюю бетку и заменить ею релиз по умолчанию.
Таким образом, у меня эта версия - unrtf-0.22.0beta.tar.gz.
Далее рекомендации по пунктам:
1. Удалить имеющуюся версию, если она инсталлирована:
sudo dpkg -r unrtf2. Скачать с архив с бетой и положить ее в домашнюю папку
3. Распаковать архив:
tar xvzf unrtf-0.22.0beta.tar.gz4. Перейти в каталог с распакованным архивом:
cd unrtf-0.22.0beta5. Выполнить команды компиляции программы:
./configure --prefix=/usr/local
make
sudo make install
6. Проверить, что новый unrtf работает:
/usr/local/bin/unrtf --html somefilewithrussian.rtf > otherfile.html
firefox otherfile.html
7. Установить Recoll
sudo apt-get install recoll8. Внести изменения в настройки Recoll
gedit /.recoll/mimeconfИ вписать
[index]
text/rtf = exec /usr/local/bin/unrtf --nopict --html
На этом почти все. Запускаем программу, идем в Настройки. Там прописываем пути к директориям, которые надо проиндексировать и ищем то, что нам надо - не только в RTF файлах, но и во всевозможных текстовых форматах, в том числе в LATEX, в LYX, в тэгах медиафайлов, в почте и IM-сообщениях, в презентациях и других видах файлов, в которых есть читабельный текст.
В общем, вот:
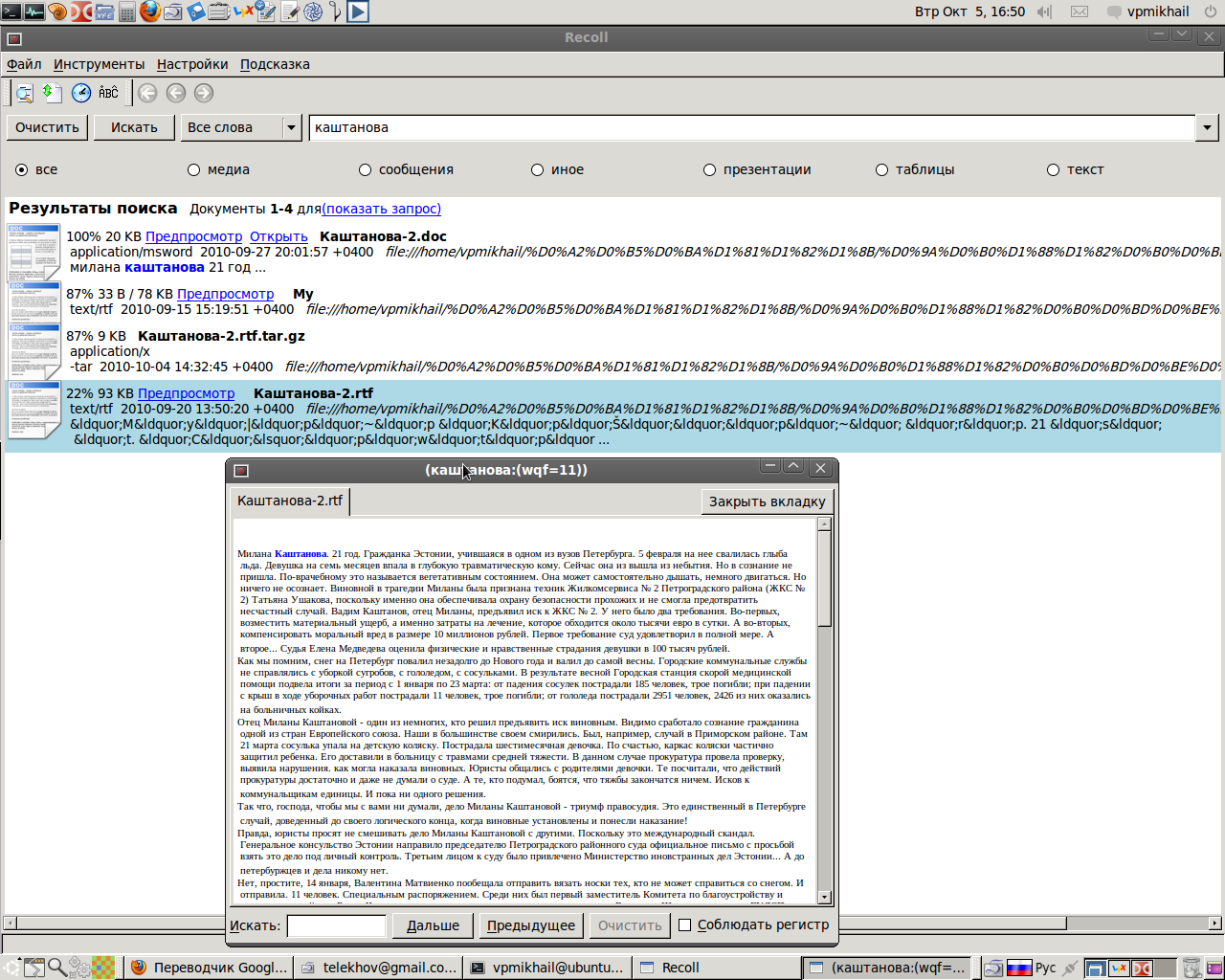
Такой скрин показан не случайно — еще один баг, который может появиться, это кракозябры в результатах поиска - в названиях русских файлов и в цитатах из текстов. Для его исправления идем в «Настройки» → «Настройки индексирования», где на вкладке «Частные параметры» ставим кодировку по умолчанию UTF-8.



Комментарии
# - Гость, 16.03.2011 в 15:14
Спасибо, полезная информация!=)
# - Артём, 12.04.2011 в 09:50
Добрый день!
У меня примерно такая же проблема, как у вас, но установка новой unrtf всё равно не помогает - русские rtf конвертятся в текст неверно. Вы не могли бы проверить, у вас конвертация в текст (
--text) выполняется нормально?Спасибо
# - maksvlad, 19.05.2011 в 18:24, в ответ на комментарий
Бился сегодя с некоторыми rtf-ками.
В общем, пляски с бубном у unrtf ничего не дали.
Вышел из положения заменой в файле
~/.recoll/mimeconfна
Catdoc прожевал все, что не смог unrtf. И было мне щастье. Через неделю экзамен, а освоить надо около дофига документов :(
Добавить комментарий